AI Agents Should Be Packages Too
A team builds an agent that works well internally. Another team wants to use it. That is where the packaging gap shows up.
- agents
- AI agent packaging
- agent package manager
- agent lockfile
- reusable AI agents
- agent interoperability
- AI agent infrastructure
AI Agents Should Be Packages Too#
A team builds an agent that works well internally. It knows which tools to call, in what order, and how to shape the output into something useful. Another team wants to use it. Then the trouble starts.
What gets shared?
Usually some mix of a repo link, a copied class, a README, a prompt doc, and a list of environment variables. The tools might already be versioned and installable. The agent itself is not. The composition still lives inside app code, framework config, or local glue that does not travel cleanly.
That is a real infrastructure gap.
We have already learned how to package reusable tools. We give them names, versions, manifests, release artifacts, and lockfiles. A second team can install the exact thing the first team published. But when the reusable unit is an agent rather than a single tool, most of that discipline disappears. The tool graph gets rebuilt by hand. The examples drift. The calling app bakes in assumptions that were never written down as a contract.
This is part of why the jump from agent prototype to production remains so messy. Organizations have adopted agents quickly, but stable production deployment is still rare. Several 2026 market summaries make the same point from different angles: agent experimentation is widespread, but production deployment remains much less common than the hype suggests.[1][2] The ecosystem has plenty of frameworks, plenty of demos, and plenty of tool reuse. What it does not have enough of is portable composition.
That composition needs to be packageable too.
The Agent That Cannot Leave the Room#
Tool packaging has crossed the reuse boundary. Agent packaging mostly has not.
If a team publishes a tool today, the rest of the organization knows how to reason about it. It has a namespaced identity. It has a version. It has a manifest. It lands in a registry. Consumers install it with a command and get the exact artifact that was published.
If the same team builds a useful agent, the story changes. The orchestration might live in LangGraph, CrewAI, AutoGen, OpenAI Agents SDK, Pydantic AI, or some internal wrapper on top of one of them. The framework landscape is active, fragmented, and still far from settled.[3] The declared tools may exist, but the composition that ties them together often stays embedded in framework-specific code. That makes the most valuable thing harder to reuse than the least valuable thing.
Three failure modes show up quickly:
- Every team rebuilds the same composition from scratch.
- An upgrade in one place does not propagate cleanly to consumers.
- No one can say with confidence which version of the agent is running in production or which tool versions it actually resolved to.
That third point matters more than it sounds. Engineers do not trust systems they cannot inspect. If a production issue traces back to an agent using a newer summarizer than expected, or a crawler with changed output behavior, the difference between declared intent and realized dependency graph becomes the whole problem.
We already know how to solve this class of problem. We solved it for libraries a long time ago. We just have not carried the same discipline far enough into agent systems.
What an AI Agent Package Actually Needs#
An agent package is not a black-box runtime. It is not a Docker image. It is not a prompt pasted into a wiki. It is not a framework export that only one ecosystem understands.
It is a portable composition artifact.
A real agent package needs the same basic properties engineers expect from any reusable artifact:
- identity
- version
- a manifest
- explicit dependencies
- install semantics
- dependency resolution
- registry presence
- documentation
- security metadata
- SDK loading surfaces
- a pinned dependency graph
That sounds like a lot until you compare it to any mature package ecosystem. This is normal infrastructure. The only unusual thing is how often agent systems still try to avoid it.
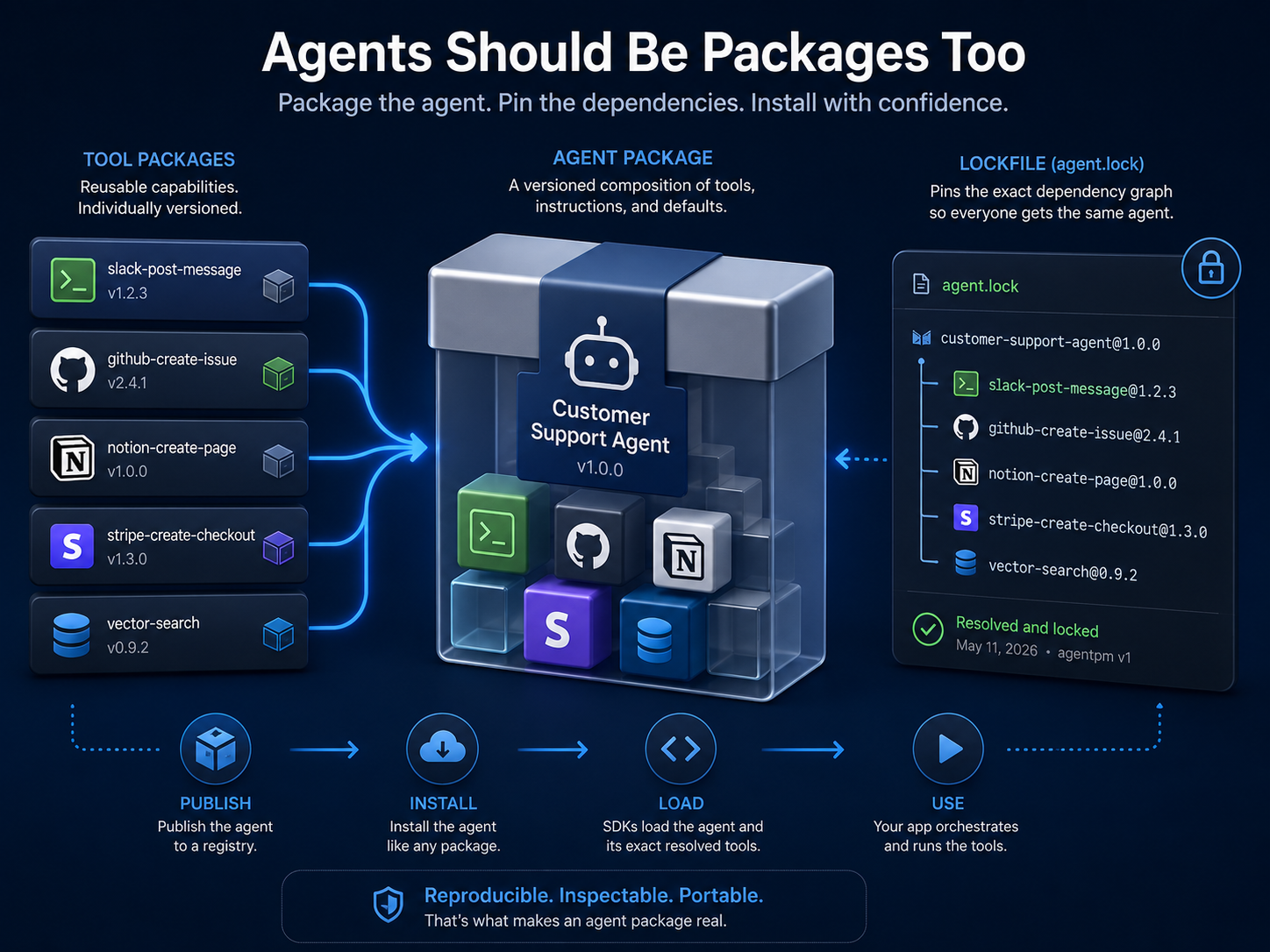
The manifest is the first piece. In AgentPM, that is agent.json. It plays the same role package.json does in JavaScript or pyproject.toml does in Python. It tells a consuming system what this artifact is called, what version it is, what tool dependencies it intends to use, and what examples or metadata go with it.
The package is about composition, not execution. The manifest says what the agent depends on. It does not force every consumer into the same orchestration model. The package does not need to dictate how the LLM loop works, how retries are handled, or how a framework chooses to call the tools. Those are runtime concerns. The package contract is narrower and more durable.
That boundary is a feature.
An agent package should tell a consuming app what to load. The app should decide how to use it.
The Agent Lockfile Is the Proof#
The manifest expresses intent. The lockfile proves what actually resolved.
Software engineers already know this pattern. A dependency range in package.json says what a project is willing to accept. package-lock.json says what it got on a specific install. That difference is why two developers can clone the same repo on different days and still end up with the same dependency graph. Lockfiles across mainstream package managers exist for exactly this reason: reproducibility, integrity, and stable installs across environments and time.[4]
Agents need the same separation.
An agent.json entry might declare a tool dependency like @zack/summarize-text@^0.1. That tells you the acceptable range. It does not tell you which exact tool version landed on disk, which integrity hash was verified, or whether the install six months from now will match the install from today.
That is what agent.lock is for.
The lockfile is where the abstract composition turns into a concrete artifact graph. It records exact package keys, exact versions, and integrity values. In practice, that means a local manifest-driven install and a direct published-agent install both become reproducible.
There are two important root types:
local:agentfor a local manifest-driven installagent:@org/name@versionfor a direct install of a published agent package
That distinction is more than bookkeeping. It lets engineers answer the questions they actually care about:
- Are we reproducing the local agent we authored, or consuming a published artifact?
- Which exact tool versions did this agent resolve to?
- Can another machine, another CI job, or another team get the same graph?
Without a lockfile, the answer to the second question becomes guesswork. With one, it becomes inspection.
An agent package that can be declared but not pinned is still too slippery to trust at scale. That matters because consistency and observability failures are still major reasons agent systems stall before production rollout.[2]
Installing and Loading Agent Packages in Practice#
The first workflow is for the agent author.
You define an agent.json, declare the tool dependencies, add examples and metadata, and run agentpm install. AgentPM resolves the declared tools, installs them under .agentpm/tools/..., and writes agent.lock. CI can then use agentpm install --frozen to reproduce that exact graph.
That workflow extends the same semantics teams already use for tools. The new part is that the composition itself now has a package contract.
The second workflow is for the consumer.
Instead of copying code or wiring local config, a consuming app can install a published agent directly:
agentpm install @zack/research-console@0.1.1That downloads the agent artifact into .agentpm/agents/..., resolves its declared tool graph, installs those tools into .agentpm/tools/..., and records the realized graph in agent.lock.
Then the SDK reads from that installed state.
In Node:
const agent = await loadAgent("@zack/research-console@0.1.1");
const firstTool = agent.resolvedTools[0];
const tool = await load(`${firstTool.name}@${firstTool.version}`);In Python:
loaded_agent = load_agent("@zack/ops-console@0.1.0")
tool_ref = loaded_agent["resolvedTools"][0]
tool = load(f'{tool_ref["name"]}@{tool_ref["version"]}')That contract is intentionally small. loadAgent() and load_agent() do not execute the agent, run the loop, or pick a framework. They return the installed manifest and the exact resolved tool references from the lockfile. The consuming app still owns orchestration.
That boundary makes the package portable.
LangGraph can consume those resolved tools. CrewAI can. A plain tool-calling loop can. An internal framework can. The package manager owns installation and dependency resolution. The runtime owns behavior.
This should feel familiar. npm does not replace React or Express. Cargo does not replace Tokio or Axum. A package manager gives frameworks and apps reproducible artifacts to consume. Agent packaging should work the same way.
Why Agent Packaging Infrastructure Matters Now#
The agent ecosystem is repeating the history of package management.
Tools crossed the reuse boundary first. That was the easy part. A single tool has clearer edges. It is easier to name, publish, version, and audit. The broader tool ecosystem now looks much more like a real package ecosystem than it did even a year ago. MCP adoption is a visible example of that shift, with public servers and SDK usage growing fast enough that “tool reuse” is now a concrete engineering concern rather than a theoretical one.[5][6]
Agents are the next boundary.
An agent built from reusable tools is still not reusable if every consuming team has to rebuild the composition by hand. That is not reuse. That is copy-paste with extra steps.
The framework churn makes this more urgent. There are too many competing agent frameworks for any team to assume the one they choose today will be the only one that matters tomorrow. If the composition is locked inside framework-specific code, portability stays low and migration costs stay high. If the composition is an installable package with explicit dependencies, the runtime can change without throwing away the artifact contract.
Governance pushes in the same direction. You cannot audit what you cannot inspect. You cannot inspect what is only implied by application code and scattered docs. A versioned, installable, pinned composition artifact gives security, platform, and application teams something concrete to reason about. That pressure is growing as analysts warn that large numbers of agentic AI efforts remain at risk when governance and operational discipline do not catch up with experimentation.[7]
That does not solve every production problem. It does solve an important one: the difference between what an agent intends to use and what it actually resolved to.
That is where AgentPM fits.
AgentPM is a concrete implementation of this pattern. It treats tools as packages, agents as packages, and the lockfile as the source of truth for the realized graph. It separates packaging from orchestration, which is exactly what makes the model portable across frameworks and usable by normal engineering teams.
The bigger point is not product-specific. The ecosystem cannot stop at packaging tools. The composition that depends on those tools needs to be an artifact too — with identity, versioning, install semantics, and a pinned dependency graph.
Otherwise the most important part of the system remains the least portable part of the system.
That pattern is old. Software teams have been using it for decades. The interesting part is not inventing something new. It is finally applying the boring, durable parts of package management to agent systems.
That is how agents stop being demos that work in one room and start becoming artifacts other teams can actually trust.
Sources#
- AI Agents Statistics 2026: Adoption, Market Growth and Key Trends: https://citrusbug.com/blog/ai-agents-statistics/
- AI Agent Scaling Gap March 2026: Pilot to Production: https://www.digitalapplied.com/blog/ai-agent-scaling-gap-march-2026-pilot-to-production
- AI Agents in Production: Frameworks, Protocols, and What Actually Works in 2026: https://47billion.com/blog/ai-agents-in-production-frameworks-protocols-and-what-actually-works-in-2026/
- The Design Space of Lockfiles Across Package Managers: https://link.springer.com/article/10.1007/s10664-025-10789-w
- 2026: The Year for Enterprise-Ready MCP Adoption: https://www.cdata.com/blog/2026-year-enterprise-ready-mcp-adoption
- MCP and A2A: The Protocols Building the AI Agent Internet: https://medium.com/@aftab001x/mcp-and-a2a-the-protocols-building-the-ai-agent-internet-bc807181e68a
- Agentic AI Statistics 2026: 150+ Data Points Collection: https://www.digitalapplied.com/blog/agentic-ai-statistics-2026-definitive-collection-150-data-points